Swe-Clarins centrum vid Linköpings universitet är placerat vid NLPLab, Institutionen för datavetenskap. Här berättar vi om två aktiviteter med anknytning till Swe-Clarin som tar sikte på att utveckla ny infrastruktur för HS-forskning.
Digitalisering av personliga berättelser
Arbetets museum har i sitt arkiv mer än 2 600 berättelser om arbete och vardagsliv. I museets arkiv finns dokumentationer av arbetsliv, skildringar av livet i industrisamhällen, om hushållsarbete på 1950- och 1960-talen samt yrkesminnen från gruvarbetare, socialsekreterare, handelsanställda m.fl. yrkeskategorier. Arbetet med att samla in berättelser är pågående och sker inom olika samhällsrelevanta områden.
Den främsta målgruppen är forskare, men ett urval berättelser presenteras i antologier, i utställningar och på museets webbsida. Vid publicering har informanterna gett sitt samtycke men äldre material i arkivet regleras inte av samtycken vilket hittills omöjliggjort att fler får ta del av museets berättelser. Internet och specifikt webben utgör den lämpligaste kanalen att göra dem publika. Det skulle också göra dem sökbara på ett helt annat sätt än hittills. Men spridning av personliga berättelser via Internet måste bygga på att berättelserna är tillräckligt anonymiserade för att personerna i dem inte ska vara identifierbara.
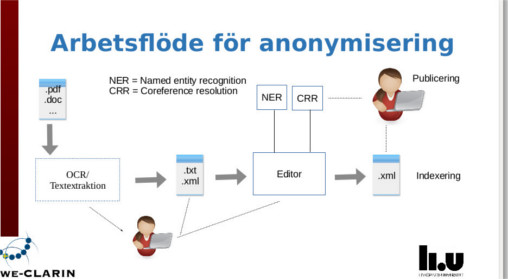
LiU:s Swe-Clarincentrum och Arbetets museum har träffats under 2016 för att diskutera möjligheterna att utveckla datorstöd för anonymisering av minnesberättelser. Vi menar att Swe-Clarins verktyg och olika kända tekniker för namnigenkänning skulle vara centrala komponenter i ett sådant datorstöd. Systemet måste naturligtvis vara interaktivt och stödja en naturlig arbetsgång på museet. Ytterst är det ju institutionen som tar ansvar för att publiceringen inte bryter mot gällande lagstiftning så som PUL.
Slutmålet för samarbetet är att utveckla ett fullständigt arbetsflöde för publicering av personliga berättelser för Arbetets museum som i tillämpliga delar skulle kunna användas av andra arkivinstitutioner. Berättelser som nu ligger som separata filer i olika format kommer därmed att kunna publiceras på Internet och göras sökbara. I projektet vill vi uppnå ett delmål i detta arbete: att säkerställa anonymiseringen och sökbarheten. Ett konkret resultat av vårens arbete är en ansökan till en extern anslagsgivare om medel för att utveckla ett arbetsflöde med stödsystem för anonymisering, uppmärkning och digitalisering av personliga minnesberättelser.
Dessa berättelser utgör en del av det svenska kulturarvet. De speglar sin tid på många sätt: historiskt, språkligt och kulturellt. De är därför av intresse för forskare med olika inriktning. En etnolog eller arbetslivsforskare som intresserar sig för hur du-reformen införts på olika arbetsplatser ska kunna söka på 'du-reform' och finna berättelser som tar upp detta. En språkforskare som vill jämföra t.ex. kvinnliga och manliga författares självpresentationer ska kunna göra detta.
Infrastruktur för lättläst och begriplighet
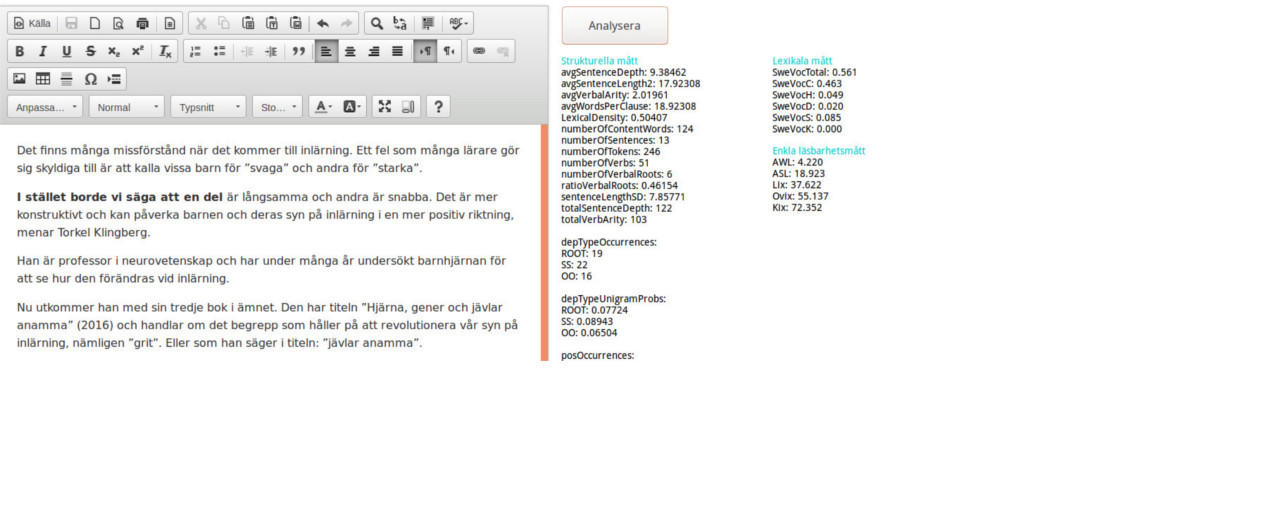
I flera projekt arbetar vi med frågor om digital delaktighet och i samband med detta samlar vi in texter från olika källor, primärt från webben, och utvärderar deras läsbarhet med både automatiska mått och läsaromdömen. De automatiska måtten kan baseras på egenskaper som ord- och meningslängd eller bygga på syntaktisk och lexikal analys av texten. De är implementerade i ett system som snabbt ger värden på en inmatad text och även kan föreslå hur texten skulle kunna förenklas (se figur).
De insamlade texterna, i förekommande fall med parallellställda normalversioner och lättlästversioner, utgör ett bidrag till en forskningsinfrastruktur om lättläst. Behovet är dock större än så. Egenskaper som läsbarhet och begriplighet är dock svårfångade och tillgången på empiriska material begränsad. Vi kommer i samarbete med Språkrådet ordna en workshop med inriktning på infrastruktur i Linköping den 30:e november. Då vill vi inventera pågående forskning och infrastrukturinitiativ när det gäller begriplighet i text med fokus på svenska och myndigheternas kommunikation med medborgarna. Syftet med workshopen är alltså att försöka staka ut en väg framåt för att skapa infrastruktur för framtidens forskning och utbildning på detta område. Information om workshopen finns här.