Språkteknologigruppen vid Uppsala universitet arbetar med att ta fram resurser och verktyg för automatisk analys och bearbetning av språkliga data. Vi vill möjliggöra storskalig kvantitativ analys av texter för forskare inom humaniora och samhällsvetenskap genom att tillgängliggöra befintliga verktyg som utarbetats för automatisk lingvistisk analys men som kan vara svåra att använda för icke programmeringskunniga.
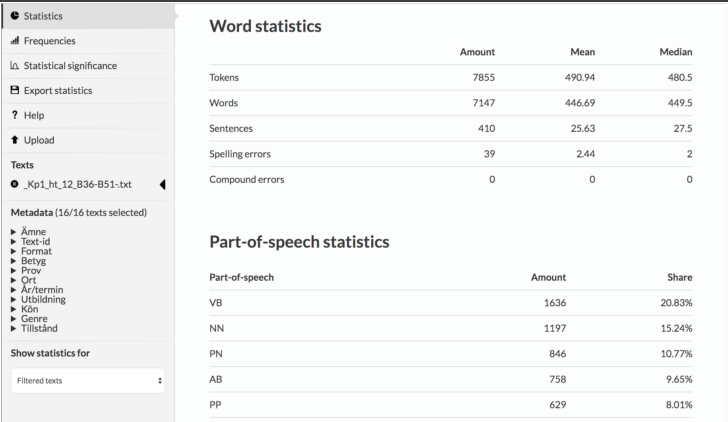
Vi har utvecklat SWEGRAM, som är en webbaserad öppen plattform där man kan ladda upp en eller flera texter på svenska och få dessa analyserade på olika språkliga nivåer. SWEGRAM ger möjlighet att segmentera texter i meningar och ord, märka upp ord med avseende på ordklass och morfologisk information, identifiera ordens basform och utföra syntaktisk analys i form av dependensrelationer på meningsnivå. Verktyget producerar också statistik om språkliga och andra textrelaterade företeelser baserad på annoteringen. Verktyget tillhandahåller statistik om exempelvis antal ord och meningar, antal ord per ordklass, olika läsbarhetsmått, stavningsfel samt frekvenslistor baserade på ord, basform eller ordklass. SWEGRAM tillåter användaren att skapa egna annoterade textsamlingar (så kallade korpusar) och att jämföra texter på olika språkliga nivåer.
Ett exempel på analys visas nedan, taget från en korpus bestående av elevtexter från nationella prov i svenska för olika årskurser som byggts med hjälp av SWEGRAM. SWEGRAM utvecklas genom ett samarbete mellan Institutionen för lingvistik och filologi och Institutionen för nordiska språk vid Uppsala universitet och finansieras bland annat av SWE-CLARIN.