
Syftet med projektet Digitalt kulturarv – ett digitalt folkminnesarkiv är att digitalisera och tillgängliggöra folkminnesuppteckningar från Institutet för språk och folkminnens samlingar. Under projektet har en databas med drygt 16 000 fulltextuppteckningar byggts upp. Förutom texterna, som består av transkriberade alternativt OCR- eller HTR-lästa uppteckningar, innehåller databasen även metadata som uppteckningsår, kategorier, insamlingsort samt upplysning om såväl upptecknare som informanter (t.ex. namn, födelseår, kön).
Både för forskare och allmänhet
Inom projektet har två plattformar skapats: Sägenkartan, som riktar sig till en bred allmänhet, och Databas över immateriella kulturarv som är en mer forskningsinriktad plattform.
Sägenkartan är kartbaserad. På kartan visas punkter som representerar socknar med uppteckningar ifrån. Klickar användaren på en punkt visas därefter en lista över sägner som är upptecknade från orten, vad uppteckningarna handlar om och vilka personer det är som har intervjuats. Det är också möjligt att ta del av uppteckningarna både som fulltext och bild. Användare som är intresserad av en sägenkategori kan istället filtrera sökresultatet så att t.ex. enbart berättelser om tomtar eller häxor visas på kartan. Med Sägenkartan har vi velat skapa en enkel och användarvänlig plattform för tillgängliggörandet av institutets äldre folkminnessamlingar.
Medan Sägenkartan enbart visar ett urval av uppteckningar från databasen så kommer hela korpusen vara tillgänglig via den mer forskningsinriktade plattformen Databas över immateriella kulturarv.
Forskningsversionen bygger på Elasticsearch som möjliggör sökning på flera olika fält i databasen samtidigt. Det är t.ex. möjligt att söka på speciellt ord i texten och begränsa resultaten så att bara uppteckningar gjorda efter kvinnliga berättare födda mellan 1848 och 1854 i Värmland visas.
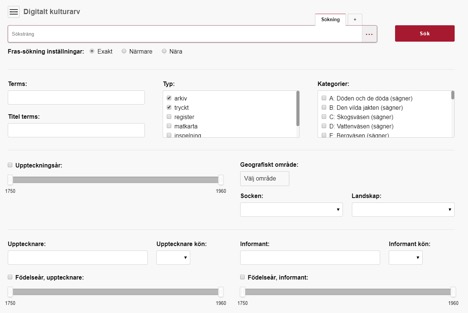
Gränssnittet visar inte bara en lista med sökresultaten utan visualiserar även statistik över metadata. Först visas en karta som åskådliggör geografisk spridning för uppteckningarna. Till skillnad från Sägenkartan bygger kartan i forskningsversionen på polygoner av olika färg: ju fler träffar från en socken, desto mörkare färg. Alternativt kan färgerna också baseras på procent av det totala antalet uppteckningar från respektive socken.
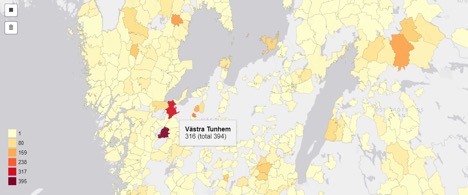
Under kartan visas olika visualiseringar som ger överblick över metadata kopplad till sökresultatet. Där använder vi funktionen i Elastic search som kallas aggregation som gör det möjligt att t.ex. hämta information om kategorier från ett sökresultat och därefter beräkna fördelningen av texter per kategori. Nedan framgår t.ex. att ordet ”spöke” oftast förekommer i kategorin ”Döden och de döda”.
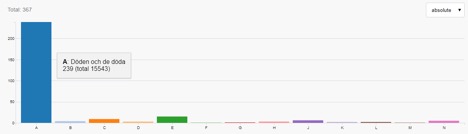
Flera visualiseringar förekommer, t.ex. linjediagram över uppteckningar per år och såväl upptecknarnas som informanternas födelseår samt stapeldiagram som åskådliggör könsfördelning.
En annan funktion är stapeldiagram över de vanligaste termerna som förekommer i respektive sökresultat. Vi har kört Latent Dirichled allocation (LDA) topic modeling på samtliga texter i databasen och använder vår topic-modell för att beräkna frekvensen av enstaka söktermer som vi därefter visualiserar. Detta ger en bild av innehållet i sökresultatet som består av många texter. Om vi fortsätter med spökexemplet, kan vi t.ex. se att de vanligaste söktermerna som har koppling till ordet spöke är “väg”, “far”, “hadd”, “natt”, “såg” och “död”.
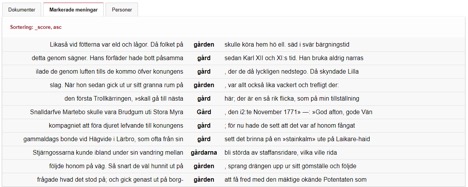
Under visualiseringsmodulerna finns även en träfflista där användaren kan läsa enstaka uppteckningar, se en lista över personer kopplade till resultatet samt en lista över markerade meningar med fokus på det ord som man har letat efter.
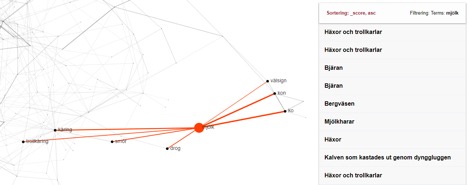
Topic modeling-data används också i en modul som visualiserar orden och kopplingar mellan dem som nätverk. Där använder vi X-Pack modulen för Elasticsearch som kan samla ihop fält från sökresultatet och hitta relationer mellan dem baserat på antal texter som innehåller samma data. Här har vi ett exempel på ett nätverk vid sökning på orden “kärring” och “käring” (stavat på två olika sätt).
Nätverksanalysen gör det möjligt att se semantiska kluster inom nätverket. I sökningen för t.ex. “kärring” kopplas ordet samman med “mjölk”, “smör”, “trollkäring” och “ko”. Samtliga ord i nätverket är klickbara. Klickar man t.ex. på ordet “mjölk” får man en lista över uppteckningar som innehåller orden “kärring” och “mjölk”. Och där kan vi se att några av dem handlar om bjäran och mjölkhare, ett väsen som häxor använde för att stjäla mjölk.
Projektet är fortfarande under utveckling och en webbaserad plattform kommer att lanseras under våren 2018.
TEXT: TRAUSTI DAGSSON & FREDRIK SKOTT